Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Short description of portfolio item number 1
Short description of portfolio item number 2
Published in IEEE International Conference on Robotics and Automation (ICRA), 2021

Published in IEEE International Conference on Robotics and Automation (ICRA), 2021

Published in IEEE International Conference on Robotics and Automation (ICRA), 2022
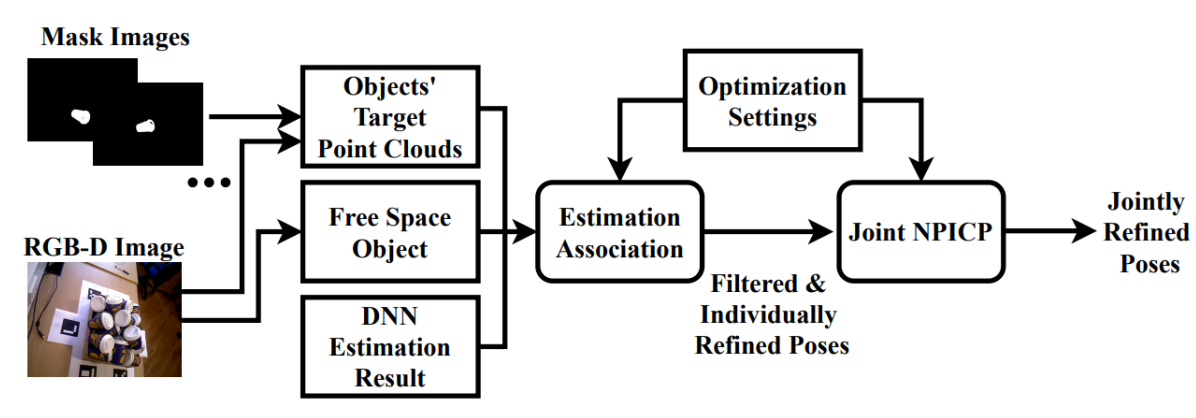
Published in Robotics: Science and Systems (RSS), 2023

Published in Workshop on Leveraging Models for Contact-Rich Manipulation at IROS 2023, 2023

Published in arXiv preprint, 2025
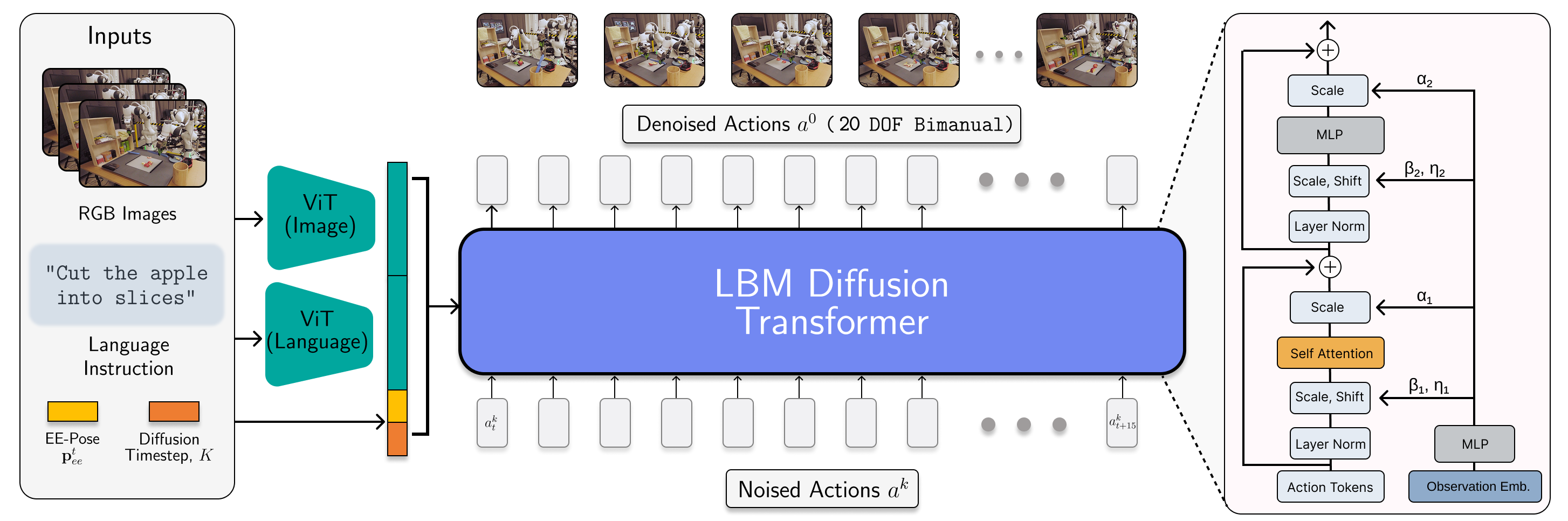
Published in Science Robotics, 2025

Published in arXiv preprint, 2025
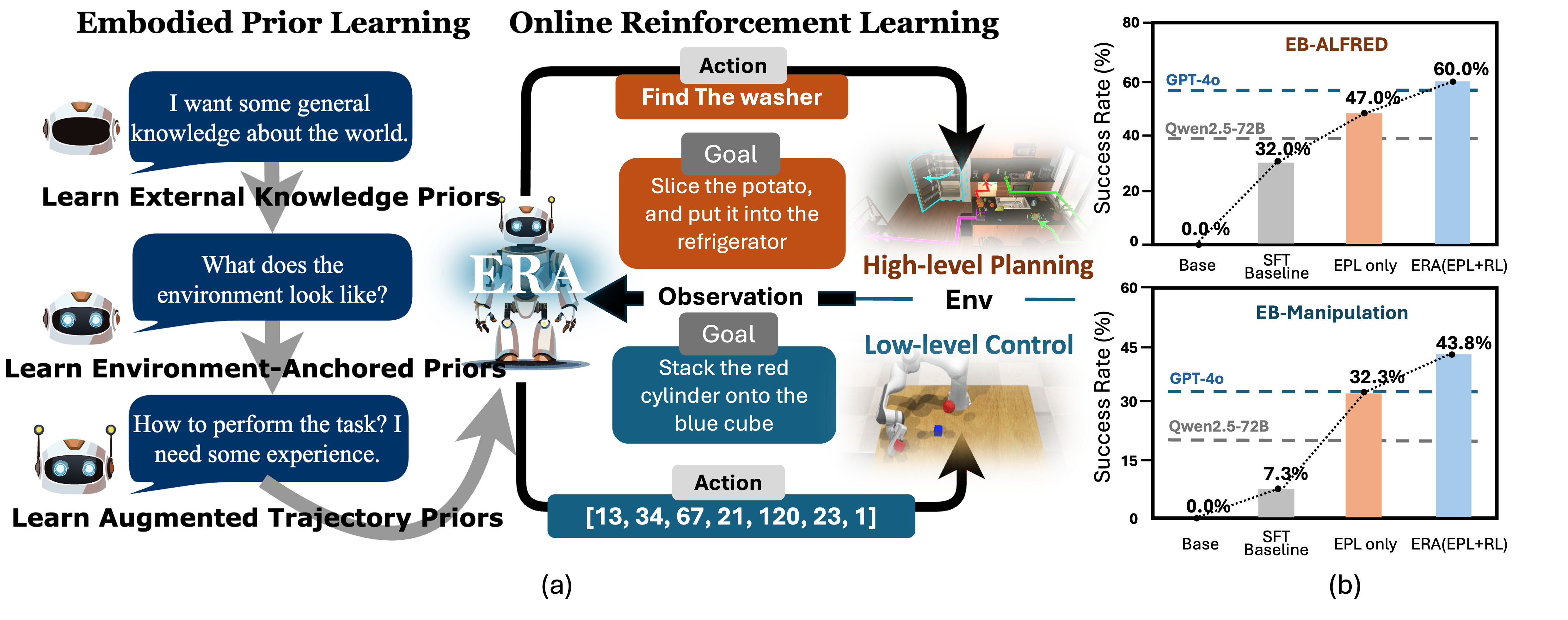
Published in arXiv preprint, 2026

Published in arXiv preprint, 2026
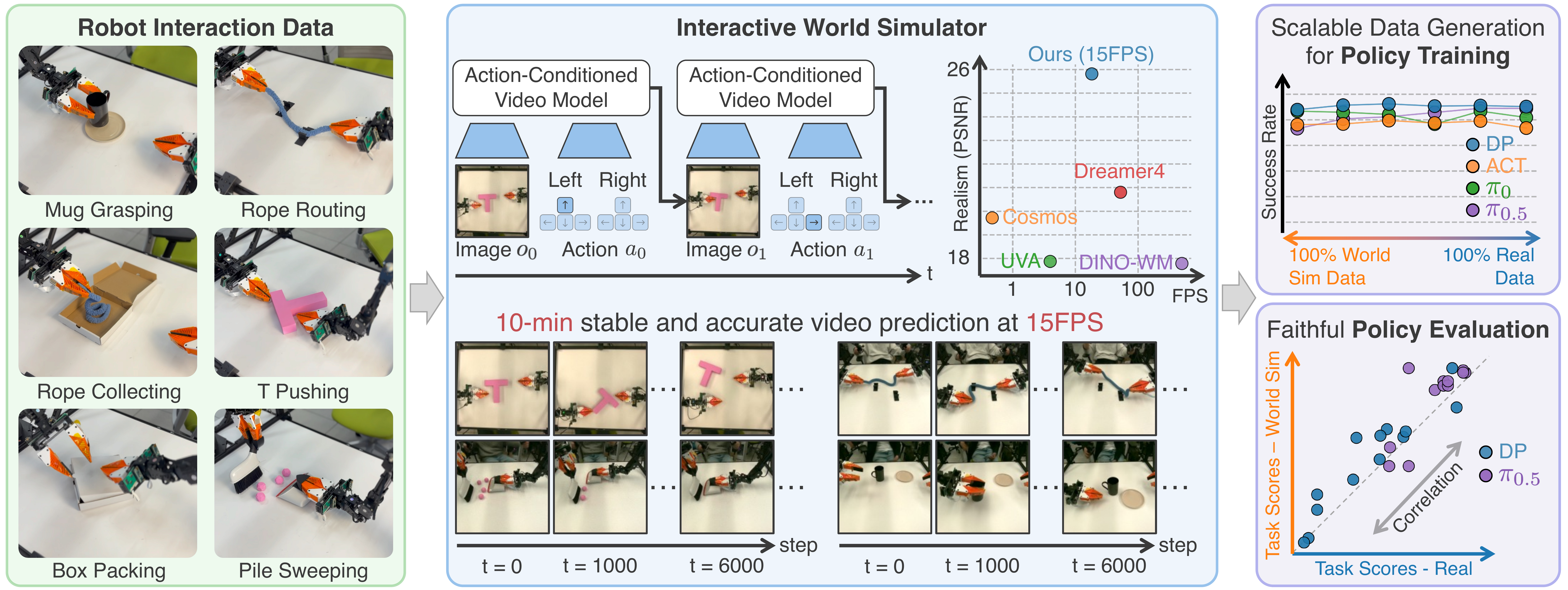
Published:
In optimization theory, semi-infinite programming (SIP) is an optimization problem with a finite number of variables and an infinite number of constraints, or an infinite number of variables and a finite number of constraints. In this talk, I will introduce our work which uses SIP to solve the problems in the field of robotics.
In the semi-infinite program with complementarity constraints (SIPCC) work, we use SIP to address the problem that contact is an infinite phenomenon involving continuous regions of interaction. Our method enables a gripper to find a feasible pose to hold (non-)convex objects while ensuring force and torque balance. In the non-penetration iterative closest points for single-view multi-object 6D pose estimation work, we use SIP to solve the penetration between (non-)convex objects. Through introducing non-penetration constraints to the framework of iterative closest points (ICP), we improve the pose estimation result’s accuracy of deep neural network based methods. Also, our method outperforms the best result on the IC-BIN dataset in the Benchmark for 6D Object Pose Estimation.
Published:
Contact-implicit trajectory optimization is an effective method to plan complex trajectories for various contact-rich systems including manipulation and locomotion. These methods formulate contact as complementarity constraints and require solving a mathematical program with complementarity constraints (MPCC). However, MPCC solve times increase steeply with the number of variables and complementarity constraints, which limits their applicability to problems with low geometric complexity. This paper introduces the simultaneous trajectory optimization and contact selection (STOCS) method that embeds the detection of salient contact points and contact times inside trajectory optimization. Because the number of active contact points is usually small, this approach minimize the number of MPCC variables and constraints, which makes solving manipulation trajectories for objects with complex, non-convex geometry computationally tractable. The proposed approach is validated on pivoting and sliding problems in simulation and on a 6 DoF manipulator arm.
Published:
Synthesizing complex whole-body manipulation behaviors has fundamental challenges due to the rapidly growing combinatorics inherent to contact interaction planning. While model-based methods have shown promising results in solving long-horizon manipulation tasks, they often work under strict assumptions, such as known model parameters, oracular observation of the environment state, and simplified dynamics, resulting in plans that cannot easily transfer to hardware. Learning-based approaches, such as imitation learning (IL) and reinforcement learning (RL), have been shown to be robust when operating over in-distribution states; however, they need heavy human supervision. Specifically, model-free RL requires a tedious reward-shaping process. IL methods, on the other hand, rely on human demonstrations that involve advanced teleoperation methods. In this work, we propose a plan-guided reinforcement learning (PGRL) framework to combine the advantages of model-based planning and reinforcement learning. Our method requires minimal human supervision because it relies on plans generated by model-based planners to guide the exploration in RL. In exchange, RL derives a more robust policy thanks to domain randomization. We test this approach on a whole-body manipulation task on Punyo, an upper-body humanoid robot with compliant, air-filled arm coverings, to pivot and lift a large box. Our preliminary results indicate that the proposed methodology is promising to address challenges that remain difficult for either model- or learning-based strategies alone.
Graduate Teaching Assistant, UIUC, Mechanical Science & Engineering Department, 2019
Professor: Leon Liebenberg
Graduate Teaching Assistant, UIUC, Mechanical Science & Engineering Department, 2020
Professor: Joao Ramos Lab Manager: Dan Block